Methodology Series Module 2: Case-control Studies PMC
Table Of Content

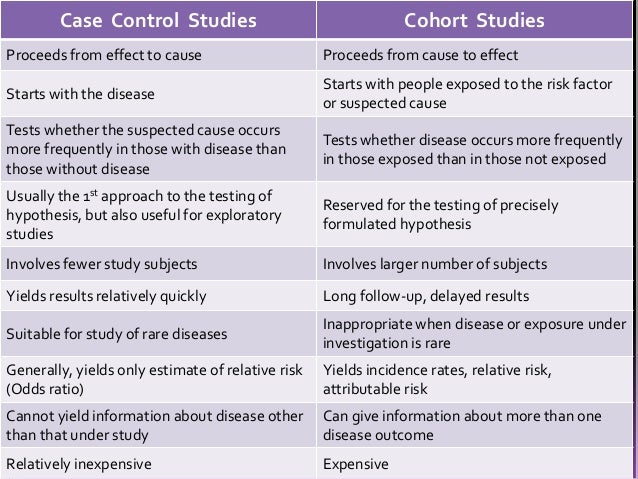
One of the most significant triumphs of the case–control study was the demonstration of the link between tobacco smoking and lung cancer, by Richard Doll and Bradford Hill. In the analysis stage, calculate the frequency of each of the measured variables in each of the two groups. As a measure of the strength of the association between an exposure and the outcome, case-control studies yield the odds ratio.

Prospective vs. retrospective cohort studies
There are not necessarily any ‘right’ answers to these questions but they must be answered before the study begins. At the end of the study, the conclusions will be valid only for patients who have the same sort of ‘endophthalmitis’ as in the case definition. They found that melanoma was higher in individuals who used UVB enhances and primarily UVA-emitting devices.
Quantifying the Drug–Outcome Association
When the subjects are enrolled in their respective groups, the outcome of each subject is already known by the investigator. This, and not the fact that the investigator usually makes use of previously collected data, is what makes case-control studies ‘retrospective’. Another important aspect of a case-control study is that we should measure the exposure similarly in cases and controls. For instance, if we design a research protocol to study the association between metabolic syndrome (exposure) and psoriasis (outcome), we should ensure that we use the same criteria (clinically and biochemically) for evaluating metabolic syndrome in cases and controls. If we use different criteria to measure the metabolic syndrome, then it may cause information bias. In a case-control study, participants are selected for the study based on their outcome status.
LIMITATIONS OF COHORT AND CASE–CONTROL STUDIES
The nested case-control study is a special situation in which cases andcontrols are both identified from within a cohort. Each patient (case)was matched with 10 randomly selected controls based on age, sex, ethnicity, and duration offollow-up. Thus, rather than extracting data for 11,314 cases and the rest of the 1,762,164adults who did not develop PD and who were therefore noncases, the authors carved out asmaller sample of controls from within the cohort. Thus, the final sample of 11,314 casesand 113,140 controls was “nested” within the original cohort; studying this smaller sampletook less time and was less labor-intensive than studying the entire cohort. After clearly defining cases and controls, decide on data to be collected; the same data must be collected in the same way from both groups.
Set-up of underlying cohort study
Physical and cognitive impact following SARS-CoV-2 infection in a large population-based case-control study ... - Nature.com
Physical and cognitive impact following SARS-CoV-2 infection in a large population-based case-control study ....
Posted: Thu, 06 Jul 2023 07:00:00 GMT [source]
Because these studies use already existing data and do not require any follow-up with subjects, they tend to be quicker and cheaper than other types of research. The “cases” are the individuals with the disease or condition under study, and the “controls” are similar individuals without the disease or condition of interest. The method of assignment of individuals to study and control groups in observational studies when the investigator does not intervene to perform the assignment. Each case is matched individually with a control according to certain characteristics such as age and gender.
Enhancing Healthcare Team Outcomes
Retrospective cohort studies use existing secondary research data, such as medical records or databases, to identify a group of people with a common exposure or risk factor and to observe their outcomes over time. Case-control studies conduct primary research, comparing a group of participants possessing a condition of interest to a very similar group lacking that condition in real time. Once cases and controls are selected, we can start to derive inverse probability weights W according to Eq. We then compute the odds of baseline exposure among cases in the pseudopopulation that is obtained by weighting everyone by W and the odds of baseline exposure among controls weighted by W multiplied by the number of times the individual was selected as a control.
Identifiability is a relative notion as it depends on which data are available as well as on the assumptions one is willing to make. Identification forms a basis for estimation with finite samples from the available data distribution [4]. Once the estimand has been made explicit and an identifying functional established, estimation is a purely statistical problem. While the identifying functional will often naturally translate into a plug-in estimator, there is, however, generally more than one way to translate an identifiability result into an estimator and different estimators may have important differences in their statistical properties.
Odds ratios are often confused with Relative Risk (RR), which is a measure of the probability of the disease or outcome in the exposed vs unexposed groups. For very rare conditions, the OR and RR may be very similar, but they are measuring different aspects of the association between outcome and exposure. The OR is used in case-control studies because RR cannot be estimated; whereas in randomized clinical trials, a direct measurement of the development of events in the exposed and unexposed groups can be seen.
Consider a case-control study intended to establish an association between the use of traditional eye medicines (TEM) and corneal ulcers. TEM might cause corneal ulcers but it is also possible that the presence of a corneal ulcer leads some people to use TEM. The temporal relationship between the supposed cause and effect cannot be determined by a case-control study. Nonetheless, matching may be useful to control for certain types of confounders. For instance, environment variables may be accounted for by matching controls for neighbourhood or area of residence.
However, they are also more likely to have similar behaviours (alcohol use, smoking etc.); thus, it may not be prudent to use these as controls if we want to study the effect of these exposures on the outcome. An important source of controls is patients attending the hospital for diseases other than the outcome of interest. These controls are easy to recruit and are more likely to have similar quality of medical records. According to them, an important aspect of selecting a control is that they should be from the same ‘study base’ as that of the cases. Thus, the pool of population from which the cases and controls will be enrolled should be same. For instance, in the Tanning and Melanoma study, the researchers recruited cases from Minnesota Cancer Surveillance System; however, it was also required that these cases should either have a State identity card or Driver's license.
It is a design that should be used more frequently in neurosurgical clinical research. Observational study designs include case-control, cohort, and cross-sectional studies, and each study is distinct with a unique role in clinical research. Case-control studies can be a robust option in neurosurgical research compared to other observational study designs. A better understanding of the differences in design type will facilitate better study designs and further improve the quality of reporting. In our review, we explored those differences and how the case-control study design can contribute to the neurosurgical literature. While both case-control and cohort studies are longitudinal by design, cross-sectional studies, often mislabeled as case-control studies, reflect a single period in time (Figure 1).
As is shown in Supplementary Appendix B, Theorem 3, the above odds ratio is identified by the ratio of the baseline exposure odds given L0 among the cases versus controls, provided the key identifiability conditions of consistency, baseline conditional exchangeability, and positivity are met. To facilitate understanding, it is useful to consider every case-control study as being “nested” within a cohort study. A case-control study could be considered as a cohort study with missingness governed by the control sampling scheme. Therefore, when the observed data distribution of a case-control study is compatible with exactly one value of a given estimand, then so is the available or observed data distribution of the underlying cohort study. In other words, identifiability of an estimand with a case-control study implies identifiability of the estimand with the cohort study within which it is nested (conceptually). In this paper, the focus is on sets of conditions or assumptions that are sufficient for identifiability in case-control studies.



Comments
Post a Comment